
1편에 이어 이번에는 소프트웨어 불법복제로 인한 피해를 살펴보겠습니다. 1편에서 다룬 저작권보호센터의 보고서는 소프트웨어를 제외한 콘텐츠(음악, 영화, 방송, 출판, 게임)만 대상으로 하고, 컴퓨터 소프트웨어의 저작권 침해로 인한 피해 규모는 한국소프트웨어저작권협회(SPC)와 소프트웨어연합(BSA)이 발표합니다.
한국소프트웨어저작권협회와 소프트웨어연합, 둘 중 한 곳은 거짓말
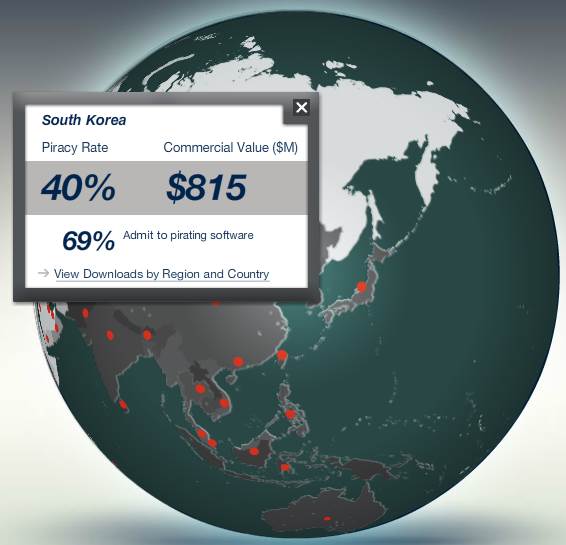 소프트웨어연합(BSA)은 「2011년 세계 소프트웨어 해적행위 보고서(2011 BSA Global Software Piracy Study)」(이하, ‘BSA 2011 보고서’)에서 한국의 소프트웨어 해적율(piracy rate)은 40%이고 피해액은 약 8천 9백억 원(미화 8억 1천 5백만 달러)으로 사상 최대치를 기록했다고 발표했습니다.
소프트웨어연합(BSA)은 「2011년 세계 소프트웨어 해적행위 보고서(2011 BSA Global Software Piracy Study)」(이하, ‘BSA 2011 보고서’)에서 한국의 소프트웨어 해적율(piracy rate)은 40%이고 피해액은 약 8천 9백억 원(미화 8억 1천 5백만 달러)으로 사상 최대치를 기록했다고 발표했습니다.
연례행사처럼 내 놓는 이 발표가 있으면 한국 언론들은 호들갑을 떱니다. 이용자의 양심을 좀 먹고 IT 산업을 경쟁력을 해친다고 다그치기도 하며, 불법복제를 근절하기 위한 교육이 필요하다는 사설까지 내 놓습니다. 행정부도 대대적인 불법복제 단속에 나섭니다. BSA는 피해액이 사상 최대인 이유를 이렇게 설명합니다.
“무엇보다 관심의 촉각을 곤두세우는 것이 소프트웨어 불법복제 피해 규모다. 국내 불법복제로 인한 손실액이 전년 대비 약 420억 원 증가한 약 8천 9백억 원(미화 8억 1천 5백만 달러)으로 증가해, 조사 이래 최대의 규모를 기록한 것 나타났다. 이는 국내 경제 규모의 확대와 고가(高價) 소프트웨어 불법복제 증가가 원인인 것으로 분석된다.”(BSA 2012년 5월 15일자 보도자료)
그런데 비슷한 시기에 SPC는 온라인 소프트웨어 불법복제로 인한 피해가 2011년에는 2010년에 비해 29%나 줄었다고 발표합니다. 피해가 이렇게 줄어든 이유는 “저작권사의 고가 SW 제품 불법복제가 크게 감소“했기 때문이랍니다.
어찌된 영문 일까요?
한 쪽은 고가 소프트웨어의 불법복제가 증가했다고 하고 다른 쪽은 고가 소프트웨어의 불법복제가 줄었다고 합니다. 양쪽 말이 다 맞으려면, “오프라인”에서 고가 소프트웨어의 불법복제가 크게 늘었어야 합니다. 왜냐하면 고가 소프트웨어의 불법복제가 줄었다고 하는 SPC의 발표는”온라인”만 조사했기 때문입니다. 그러나 오프라인에서 이런 일이 생겼다는 얘기는 누구도 하지 않고, 실제로도 그런 일이 없었습니다. 결국 BSA와 SPC 중 어느 한 곳은 거짓말을 하는 셈입니다. 제가 보기에 BSA보다 SPC의 발표가 더 정확할 것 같습니다. SPC는 실제 모니터링을 통해 조사결과를 내기 때문입니다.
소프트웨어연합(BSA), 겨우 6천명으로 전 세계 불법복제율 계산, 한 나라당 214명 꼴
그럼 BSA는 소프트웨어 불법복제율을 어떻게 계산할까요? 직접 하지 않고 IDC (International Data Corporation)란 곳에 맡겨서 계산합니다. IDC는 아주 간단한 아래 수식을 씁니다.
 PC에 설치된 소프트웨어 유닛의 개수를 분모에 놓고 불법복제된 소프트웨어 유닛의 개수를 분자에 놓으면 끝입니다. 문제는 이 수식의 분모값과 분자값을 어떻게 구하느냐 입니다. 이 사이트에 가면 분모값과 분자값을 어떻게 구하는지 IDC 대표가 직접 설명하는 동영상과 방법론이 나와있습니다. 이 사이트에서도 IDC가 파워포인트로 설명하는 동영상을 볼 수 있습니다.
PC에 설치된 소프트웨어 유닛의 개수를 분모에 놓고 불법복제된 소프트웨어 유닛의 개수를 분자에 놓으면 끝입니다. 문제는 이 수식의 분모값과 분자값을 어떻게 구하느냐 입니다. 이 사이트에 가면 분모값과 분자값을 어떻게 구하는지 IDC 대표가 직접 설명하는 동영상과 방법론이 나와있습니다. 이 사이트에서도 IDC가 파워포인트로 설명하는 동영상을 볼 수 있습니다.
이 설명에 따르면, 위 수식에서 분모값은 어느 국가에서 일년동안 설치된 모든 PC의 개수를 구한 다음 여기에 PC 하나당 설치된 소프트웨어 유닛의 개수로 구합니다. 이를 위해 모두 182개의 입력값을 사용한다고 하는데 가장 중요한 값은 PC 한대당 설치된 소프트웨어의 개수입니다.
2009년 BSA 보고서의 경우, 28개 국가의 4천 개 이상의 사업 부문에서 6천명을 상대로 설문조사를 하여 PC당 소프트웨어 개수를 구합니다. 한 나라당 평균 214명을 조사하는 꼴입니다. 그리고 전세계 국가가 230 여개 정도인데 IDC는 이 중 약 8%만 선별해서 조사합니다. 표본 조사를 하지 않은 국가의 경우에는 표본 조사를 한 28개국의 데이터를 변환하는데, 여기에는 ITU (International Telecommunication Union)에서 발표한 신흥시장 척도값(ICT Development Index라고 함)을 적용한다고 합니다(BSA 2011 보고서 12면 왼쪽 칼럼 참조). 이 값으로 국가를 6개의 집단(기존의 4개 집단에서 확대)으로 나누어 표본 조사를 하지 않은 국가의 PC 한 대당 설치된 총 소프트웨어의 개수를 추정하고, 이를 소프트웨어 가치(ASV: Average System Value)로 나누어 유닛으로 환산합니다.
전환율 100%라는 터무니없는 가정
겨우 8%의 국가에서 6천명을 표본조사하여 전 세계 소프트웨어 불법복제율을 산정하고 이를 대대적으로 공표하는 IDC의 과감함도 놀랍지만, 분자값을 구하는 방식은 더 놀랍습니다.
이왕 표본조사를 했다면 조사대상자들이 비용을 지불하지 않고, 또는 불법으로 설치한 소프트웨어의 개수를 구해서 분자에 놓으면 될텐데, IDC는 이렇게 계산하지 않습니다. 복잡한 방식으로 분자값을 계산하는데, 우선 IDC는 합법적으로 구매한 소프트웨어 시장의 가치를 산정합니다. 이 시장 가치를 소프트웨어 유닛의 개수로 환산하기 위해 IDC는 해당 국가의 모든 PC 소프트웨어의 단위 평균 가격을 계산합니다. 합법 소프트웨어 유닛은 “소프트웨어 시장 가치”를 “소프트웨어 유닛 평균 가격”으로 나눈 값이 되고, 따라서 위 수식의 분자값 “해적 소프트웨어 유닛”은 PC 한 대에 설치된 “총 소프트웨어 유닛”에서 “합법 소프트웨어 유닛”을 뺀 값이라고 합니다(BSA 2011 보고서 12면).
왜 이런 복잡한 방식으로 분자값을 계산할까요? 바로 전환율이 100%라고 보기 위해서입니다. 현재 PC에 설치되어 있는 소프트웨어 중 비용을 지불하지 않은 소프트웨어는 불법복제를 근절했을 때 모조리 정품 소프트웨어의 구매로 전환된다는 것이 IDC의 가정입니다. 이런 가정이 터무니없다는 점을 잘 알기 때문에, IDC는 이것이 잘 드러나지 않도록 무슨 말인지 알기 어려운 복잡한 방식으로 “해적 소프트웨어 유닛”을 계산한 것입니다.
hurips님처럼 깊게 자료 조사를 해보진 않았습니다만(게을러서 링크해주신 자료들도 아직 못봤습니다. 나중에 천천히 살펴보겠습니다), 대체로 말씀에 동조합니다. 다만, 논지와는 좀 다른 엉뚱한 얘기가 될지도 모르겠습니다만, 저는 전환율 100%라는 것보다, 유닛 값을 어떻게 산정하는지에 문제가 있다고 생각합니다.
국내의 사정에만 한정된 것인지는 모르겠습니다만, 제 경험상 기업체를 상대로 판매하는 소프트웨어의 경우 “정가”대로 팔리는 경우는 거의 없습니다. 대부분 국내 총판업체들이 할인율을 적용해서 판매합니다. 그러나 불법복제 단속에 걸리면 정가를 기준으로 피해금액을 주장합니다.
물론 불법복제본을 쓰는 것부터 잘못된 행위임에는 의문의 여지가 없습니다. 게다가 미국처럼 징벌적 손해배상까지 인정하는 법제에 비교해보면 피해금액을 정가 기준으로 하는 것이 오히려 침해자에게 관대하다고 할 수도 있겠지요. 다만, 최소한 국내 법제를 전제로 하면, 정가와 실제거래가의 이중 가격 구조를 만들어놓고 단속시 정가 기준으로 배상을 요구해오는 행태는 좀 문제가 있다고 생각합니다.
전환율 100%는 꼭 잘못된 주장은 아니라고 생각합니다. 저작권자가 가격을 터무니없이 높게 형성해놨다면, 안쓰면 되는 것이지 “너무 비싸서 불법복제본을 썼다”는 것은 정당한 항변이라고 보기는 어려우니까요. 실제로 우리 저작권법상으로도, 저작자의 허락을 받지 않고 복제하면 그 자체로 일단 손해배상은 (실거래가를 기준으로) 인정되고, “가격이 터무니 없이 비싸므로 침해자가 정품을 샀을 리가 없다”는 이유로 손해 자체를 부정하지는 않습니다(다만 액수에 반영합니다). 다만… “안쓰면 된다”는 것도 항상 맞는 말이라고 할 수는 없습니다. 표준이라는 것이 존재하고, 안쓸 수 없는 소프트웨어들이 있으니까요. 여기까지 가면 논의가 너무 복잡하고 어려워지네요.
통계 조사의 설계 단계부터 어떻게 하는 것이 옳은 것인지에 대해 논의가 있어야 할 것 같습니다. 저도 말은 이렇게 하면서 뭐가 정답인지는 잘 모르겠습니다.
두서없는 댓글 읽어주셔서 감사합니다.